Goodbye Latent Space? How HiDream-O1-Image is Revolutionizing General-Purpose AI Drawing

- HiDream-O1-Image uses a general-purpose UiT architecture
- The “work is visible” to humans
- Potential for dramatic performance improvements in Qwen-VL models
Introduction
Hello, this is Easygoing.
This time, I’d like to introduce the new image generation AI HiDream-O1-Image, which was released on May 8, 2026.

HiDream.ai is a Chinese AI Startup
HiDream.ai is an AI startup company headquartered in Beijing, China.
gantt
title HiDream.ai models
dateFormat YYYY-MM-DD
tickInterval 12month
axisFormat %Y
HiDream-I1-Full : 2025-04-06, 2026-05-15
HiDream-I1-Dev : 2025-04-06, 2026-05-15
HiDream-I1-Fast : 2025-04-06, 2026-05-15
HiDream-E1-Full : 2025-04-27, 2026-05-15
HiDream-E1.1 : 2025-07-16, 2026-05-15
HiDream-O1-Image : crit, 2026-05-15, 2026-05-15
The HiDream-I1 model released by HiDream.ai in April 2025 was a high-performance image generation AI equipped with four text encoders. It caused a global sensation because it was released under the MIT license, allowing free development and commercial use.
About HiDream-I1
While the HiDream-I1 model had excellent prompt understanding, it was computationally heavy for local execution. Additionally, because it was trained on images converted to JPEG, it had the drawback of reproducing JPEG noise. Unfortunately, it did not gain widespread adoption among general users.
However, the HiDream-O1-Image model that appeared on May 8, 2026, brings an even greater impact than the previous HiDream-I1, so I’d like to introduce its features to you all.
Image Generation is Handled by Three Specialized AIs Working Together
Image generation is performed through the division of labor among three AIs.
flowchart TB
subgraph Checkpoint
A1(Text Encoder)
B1(Unet / Transformer)
C1(VAE)
end
- Text Encoder: Analyzes the prompt
- UNet / Transformer: Generates the image
- VAE: Compresses the space
First, when the user says “Draw a picture,” an AI that understands human language (mainly English and Chinese) converts the instruction into machine language (vectors).
Image Generation Workflow


Then, based on that vector, an AI specialized in drawing retreats into its own dedicated studio (latent space) and works 12 times more efficiently, diligently creating the image.
The finished painting is in a format only the drawing AI can understand (it looks like static noise to humans), so it is decoded (VAE decode) to produce an image visible to humans.
gantt
title Image Generative AI Roadmap
dateFormat YYYY-MM-DD
tickInterval 12month
axisFormat %Y
section Stability AI
Stable Diffusion 1 : 2022-08-22, 2026-05-15
Stable Diffusion XL : 2023-07-26, 2026-05-15
Stable Diffusion 3 : 2024-06-12, 2026-05-15
section Fal.ai
AuraFlow : 2024-07-12, 2026-05-15
section Black Forest Labs
Flux.1 : 2024-08-01, 2026-05-15
Flux.2 : 2025-11-25, 2026-05-15
section DeepSeek.ai
janus-pro : 2025-01-25, 2026-05-15
section Zhipu AI
CogVideoX : 2024-08-06, 2026-05-15
GLM-Image : 2026-01-12, 2026-05-15
section Rhymes AI
Allegro : 2024-10-22, 2026-05-15
section Genmo
Mochi : 2024-10-25, 2026-05-15
section Tencent
Hunyuan video : 2024-12-03, 2026-05-15
Hunyuan image : 2025-09-09, 2026-05-15
section lllyasviel
Framepack : 2025-04-17, 2026-05-15
section Lightricks
LTX : 2024-12-11, 2026-05-15
section StepFun
Step-Video-T2V : 2025-02-17, 2026-05-15
section Alibaba
Wan : 2025-02-25, 2026-05-15
Qwen-Image : 2025-08-04, 2026-05-15
Z-Image : 2025-11-25, 2026-05-15
section NVIDIA
Cosmos-Predict2 : 2025-04-30, 2026-05-15
section CircleStone Labs
Anima : 2026-01-26, 2026-05-15
section Baidu
ERNIE-Image : 2026-04-07, 2026-05-15
section HiDream.ai
HiDream-I1 : 2025-04-06, 2026-05-15
HiDream-O1-Image : crit, 2026-05-08, 2026-05-15
This has been the method used by all image generation AIs since the release of Stable Diffusion 1.
HiDream-O1-Image Does Everything by Itself!
Now, let’s take a look at how HiDream-O1-Image processes images.
HiDream-O1-Image is a model that extends the large language model (chat AI) called Qwen3-VL by adding image generation capabilities.
HiDream-O1-Image Workflow
flowchart TB
A1(User)
B1(HiDream-O1-Image)
A1--"Draw a picture"-->B1
B1--"Here you go!"-->A1
HiDream-O1-Image understands language and images in the same dimension (UiT: Pixel-level Unified Transformer architecture) and draws pictures by itself.
Since it doesn’t retreat into its own dedicated studio, humans can sequentially check what parts it is modifying.
Furthermore, because it draws human-visible images directly, there is no need for decoding, and thus no image quality degradation caused by decoding.
About Image Quality Degradation Caused by VAE
HiDream-O1-Image is a groundbreaking AI model that proves a general-purpose AI can generate illustrations without needing a specialized drawing AI.
General-Purpose AI Has Many Advantages
General-purpose AI offers numerous benefits.
Simplified Workflow
As you can see from the diagram above, using a general-purpose model greatly simplifies the workflow.
A simpler workflow naturally leads to faster processing. It also eliminates the need to carefully manage information passed between AIs, making adjustments much easier.
Additionally, there have been frequent cases recently of malware being injected into libraries used by AI. With fewer models to use, fewer libraries are required, which also reduces security risks.
Lighter than Z-Image
The common belief for the past four years since image generation AI emerged has been that “latent space is necessary for AI to generate images efficiently.” HiDream-O1-Image shattered this belief with the UiT architecture using a model that is only one-third the size of its predecessor — which is truly astonishing.
Processing Language and Images in the Same Dimension
By processing language and images in the same dimension, HiDream-O1-Image can perform image editing much more naturally than before.
Image Editing Examples with HiDream-O1-Image








AI acquires desired functions by ingesting massive amounts of information, but the details remain a black box.
With the arrival of the HiDream-O1-Image model, which processes language and images in the same dimension without using latent space, we can expect progress in the understanding of image generation AI models themselves.
What Will Happen Next?
HiDream-O1-Image is built on Alibaba’s Qwen3-VL model.
As of May 2026, the Qwen series has established itself as the de facto standard text encoder for image generation thanks to its high performance and open license.
Text Encoders for Image Generation AI Models
| Developer | Model | Text Encoder | Encoder Developer |
|---|---|---|---|
| — CLIP Generation (~2023) — | |||
| Stability AI | Stable Diffusion 1.x | CLIP-L (0.1B) | OpenAI |
| Stable Diffusion XL | CLIP-L (0.1B) OpenCLIP-G (0.7B) |
OpenAI LAION |
|
| — T5 Generation (2024~) — | |||
| Stability AI | Stable Diffusion 3 | CLIP-L (0.1B) OpenCLIP-G (0.7B) T5-XXL-v1.1 (11B) |
OpenAI LAION |
| Fal.ai | AuraFlow | pile-T5-XL (3B) | EleutherAI / Google |
| Black Forest Labs | Flux.1 [schnell / dev] | CLIP-L (0.1B) T5-XXL-v1.1 (11B) |
OpenAI |
| DeepSeek | Janus-Pro | SigLIP-L (0.4B) DeepSeek-LLM (7B) |
Google DeepSeek |
| Zhipu AI | CogVideoX | T5-XXL (11B) | |
| GLM-Image | GLM-4-9B (9B) Glyph Encoder |
Zhipu AI | |
| Genmo | Mochi | T5-XXL-v1.1 (11B) | |
| Rhymes AI | Allegro | T5-XXL (11B) | |
| Lightricks | LTX-Video | T5-XXL-v1.1 (11B) | |
| NVIDIA | Cosmos-Predict2 | T5-XXL (11B) | |
| — Proprietary LLM Generation (2025~) — | |||
| HiDream-ai | HiDream-I1 | CLIP-L (0.1B) OpenCLIP-G (0.7B) T5-XXL-v1.1 (11B) Llama-3.1-Instruct (8B) |
OpenAI LAION Meta |
| Tencent | Hunyuan Video | LLaVA-LLaMA-3 (8B) CLIP-L (0.1B) |
Xtuner / Meta OpenAI |
| Hunyuan Image | Proprietary MLLM | Tencent | |
| StepFun | Step-Video-T2V | Hunyuan-CLIP Step-LLM |
Tencent StepFun |
| Alibaba | Wan (2.1 / 2.2) | UMT5-XXL (13B) | |
| Qwen-Image | Qwen2.5-VL (7B) | Alibaba | |
| Z-Image | Qwen3 (4B) | Alibaba | |
| Black Forest Labs | Flux.2 [dev] | Mistral Small 3.2 / Pixtral (24B) | Mistral AI |
| Flux.2 [klein] 9B | Qwen3 (8B) | Alibaba | |
| Flux.2 [klein] 4B | Qwen3 (4B) | Alibaba | |
| CircleStone Labs | Anima | Qwen3-Base (0.6B) | Alibaba |
| Baidu | ERNIE-Image | Mistral3 Pixtral (3.3B) |
Mistral AI |
| HiDream-ai | HiDream-O1-Image | Qwen3-VL (8B) | Alibaba |
HiDream-O1-Image’s technology can naturally be reverse-imported back into the main Qwen project, so it is certain that the image recognition and generation capabilities of the Qwen-VL series will improve dramatically.
Furthermore, it has already been revealed that a high-performance model with more than 200B parameters based on the HiDream-O1-Image model exists.
The UiT architecture released under the MIT license with HiDream-O1-Image is likely to become the new standard for image generation. We can foresee a future in which current image generation AIs will be restructured under the UiT architecture.
And if the UiT architecture is introduced into ultra-large-scale cloud AIs such as ChatGPT or Gemini, it is beyond the author’s imagination what will become possible.

How to Use HiDream-O1-Image!
Let me show you how to use the HiDream-O1-Image model in ComfyUI.
ComfyUI added support for HiDream-O1-Image on May 13, 2026, but the default workflow is quite complex. Here, I’ll introduce my own custom node that implements HiDream-O1-Image in a simple way.
ComfyUI-uit-hidream-o1 Custom Node

Models
- Comfy-Org (Recommended)
- HiDream-O1-Image_clear (Clear Model)
- HiDream-O1-Image (Official)
- HiDream-O1-Image-Dev (Official)
- HiDream-O1-Image-Dev-2604 (Official)
Text to Image

Image to Image

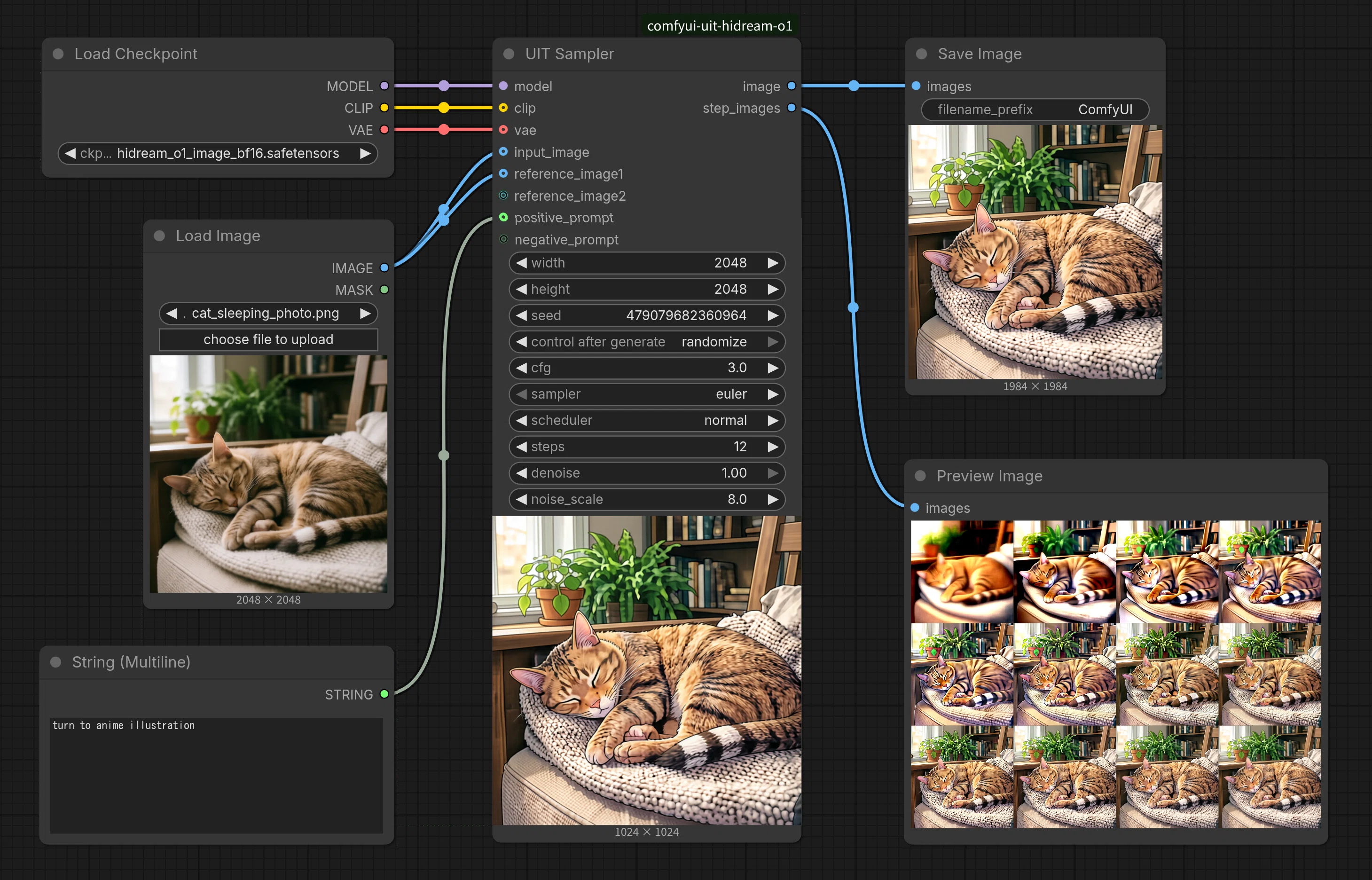
Image Edit

Summary: The Future Where General-Purpose AI Freely Draws Images
- HiDream-O1-Image uses a general-purpose UiT architecture
- The “work is visible” to humans
- Potential for dramatic performance improvements in Qwen-VL models
This time, I introduced the HiDream-O1 model.
HiDream is one of my favorite model series, and I am delighted that they have released a new model that directly challenges the fundamental propositions of image generation AI and breaks common sense.

Two years have passed since Alibaba began releasing the Qwen models under open licenses, and one year since the HiDream models. Based on their track record so far, the author trusts both companies’ commitment to open source.
The field of image generation AI is still full of potential for major transformation, and I am excited to see what kind of future awaits us.
Thank you for reading until the end!
Update History
2026.5.31
Replaced the custom node with ComfyUI-uit-hidream-o1
2026.5.17
Corrected the section regarding ComfyUI support for HiDream-O1-Image